Программное обеспечение
Мы на GitHub:

TopicMiner
Разработчики: С. Кольцов и В. Филиппов.
Интерфейсное приложение с закрытым исходным кодом для препроцессинга текстовых данных, тематического моделирования и визуального анализа результатов.
Языки программирования: C++, Delphi, and CUDA.
Период разработки: Сентябрь 2012 — настоящее время.
Технические характеристики
TopicMiner использует целый ряд библиотек и пакет AlphaControls/AlphaSkins (для Delphi) с закрытым исходным кодом для графического интерфейса. Одной из ключевых особенностей TopicMiner является возможность работы с большими объемами текстовых данных (десятки и сотни тысяч документов, гигабайты данных). Модуль препроцессинга использует библиотеки crc32lib (трансформация слов в crc32 коды). Модуль тематического моделирования основан на библиотеках bigartm, gibbsLDA, hdplib. В настоящий момент исходный код TopicMiner закрыт и не может быть открыт из-за лицензионных ограничений используемых им библиотек (с закрытым исходным кодом).
Характеристики модулей
- Модуль препроцессинга
- Импорт данных из текстовых файлов и CSV-файлов;
- Очистка текстов;
- Лемматизация текстов на английском и русском языках (при помощи Yandex Mystem);
- Расчет частот слов;
- Создание списка стоп-слов;
- Удаление стоп-слов из документов.
- Модуль тематического моделирования
- Высокоэффективные алгоритмы: LDA с сэмплированием Гиббса, ISLDA, Гранулированная модель LDA, BigARTM, PLSA (с регуляризаторами);
- Установка параметров для тематического моделирования: число тем, коэффициенты α и β, число итераций, число потоков, регуляризация);
- Выгрузка результатов тематического моделирования (распределение слов и документов по темам);
- Выгрузка результатов тематического моделирования в геоинформационную систему QuantumGIS;
- Расчет матрицы расстояний между словами в документах в заданной теме.
- Диагностика и визуализация качества тематических моделей
- Оценка качества модели и его визуализация (доля слов и документов, вероятность которых выше средней пороговой;
- Сравнение тем с помощью расстояния Кульбака-Лейблера и индекса Жаккара.
Скачать: TopicMiner (ZIP, 37.41 Mb)
Краткая инструкция: TopicMiner Краткая инструкция (PDF, 1.13 Мб)
Руководство по использованию: TopicMiner Руководство (PDF, 2.96 Мб)
Научные публикации: Список публикаций (PDF, 79 Кб)
Информационная система реализована в виде инсталлятора для операционных систем: Microsoft Windows 8 и выше (64 бит). Доступ к программе осуществляется по запросу: linis-spb@hse.ru
FakeNews App
Разработчик: Максим Терпиловский.
Языки программирования: Python и JavaScript.
Период разработки: 2019 — 2022.
Приложение было разработано для сбора данных в рамках проекта FakeNews. Оно основано на клиент-серверной архитектуре и включает две версии: веб-сайт и приложение сообщества ВК. Интерфейс приложения оптимизирован под все виды платформ и включает элементы геймификации. Приложение демонстрирует пользователю несколько новостей и просит оценить степень доверия к ним. Для получения обратной связи пользователю необходимо ответить на несколько вопросов анкеты. Приложение запрашивает доступ к приватным данным пользователя и получает информированное согласие (только для ВК).
На основе этого приложения были создана специальная версия, адаптированная для нашего проекта EyePoint. Эта версия включает экраны калибровки и QR-метки для ай-трекера.

VKMiner (Social Network)
Доступ к программе осуществляется по запросу: linis-spb@hse.ru
Информационная система для работы с социальной сетью "ВКонтакте".
Язык разработки: Delphi XE2, SQL
Время разработки: 02.2013 – наст.вр.
Разработчики: С. Кольцов, В. Филипов.
Возможности:
- Загрузка персональные данные пользователей из списка Id
- Загрузка списка друзей конкретного пользователя.
- Загрузка списка групп конкретного пользователя.
- Загрузка списка пользователей конкретной группы.
- Расчет эго сети (Network of friends).
- Загрузка исходных данных для сети друзей.
- Засчет сети друзей.
- Загрузка данных со стены пользователя или группы.
- Загрузка списка обсуждений и самих обсуждений со стены.
- Загрузка 'Discussion'
- Загрузка 'Group Distribution'.
- Загрузка 'Group Distribution'.
- Загрузка 'Random User sampling'.
- Загрузка 'Network of freinds + wall'.
- Выгрузка результатов загрузки в формате csv.
- Загрузка 'User parameter profile'.
- Мониторинг процесса загрузок.
DigiFriends App
Разработчик: Максим Кольцов.
Языки программирования: Python и JavaScript.
Приложение было создано для сбора данных в рамках исследовательского проекта Digital Friends (DigiFriends) и внедрено в социальную сеть Вконтакте. Таким образом, полученные данные касаются пользователей социальной сети Вконтакте. В основе приложения лежит анкета, вопросы которой касаются целого ряда характеристик пользователя (см. ниже).
Психологические и социально-демографические особенности пользователя:Особенности онлайн-поведения:
- склонность устанавливать социальные связи [1];
- уровень самооценки [2];
- уровень субъективного благополучия;
- социально-демографические характеристики (пол, возраст, уровень образования).
Социальный капитал пользователя:
- подверженность рискам приватности в Сети [3];
- поведение в области приватности в социальной сети Вконтакте;
- частота и продолжительность пребывания в социальной сети Вконтакте;
- цели использования социальной сети Вконтакте.
- шкала воспринимаемого социального капитала [4].
Всего анкета содержит 42 вопроса.
В приложение встроена функция сбора данных из личного профиля пользователя в Вконтакте: анкетные данные, ID друзей пользователя, характеристики активности пользователя на "стене". Все данные собираются с согласия пользователя, до начала заполнения анкеты и сбора данных пользователя информируют о том, какие данные собираются в рамках исследовательского проекта. Сбор данных начинается после того, как пользователь нажмет кнопку "Начать".
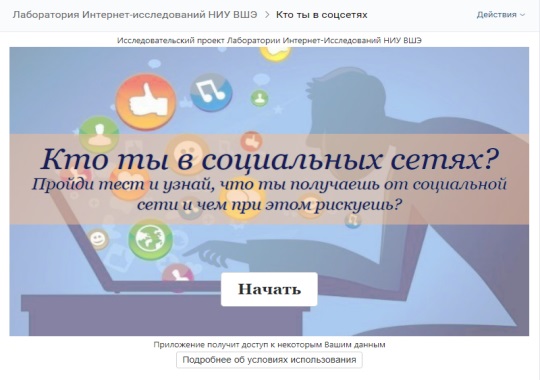
По итогу заполнения анкеты, приложение генерирует обратную связь для пользователя, основываясь на его ответах.

Ссылки:
[1] Totterdell P., Holman D., Hukin A., "Social networkers: measuring and examining individual differences in propensity to connect with others," Social Networks, vol. 30, pp. 283-296, 2008.
[2] Rosenberg, M. (1965). Society and the adolescent self-image. Princeton, NJ: Princeton University Press.
[3] Stutzman, F., Capra, R., & Thompson, J. (2011). Factors mediating disclosure in social network sites. Computers in Human Behavior, 27(1), 590-598
[4] Williams, D. (2006). On and off the’Net: Scales for social capital in an online era. Journal of computer-mediated communication, 11(2), 593-628.
LINIS-CROWD
LINIS-CROWD — это веб-приложение, предназначенное для краудсорсинговой разметки текстовых данных. Данная система была использована для разработки русскоязычного сентимент-словаря, ориентированного на социально-политическую тематику.
Вы можете больше узнать о LINIS-CROWD в данной публикации:
Алексеева, С. В., Кольцов, С. Н., & Кольцова, О. Ю. (2015). Linis-crowd.org: лексический ресурс для анализа тональности социально-политических текстов на русском языке. In XVIII Объединенная научная конференция «Интернет и современное общество» (IMS‑2015) (pp. 25–34). Санкт-Петербург. URL: http://openbooks.ifmo.ru/ru/file/2203/2203.pdf
Веб-платформа и сентимент-словарь доступны по ссылке. По вопросам использования баз данных и программного обеспечения, разработанного в ЛИНИС, обращаться по адресу: linis-spb@hse.ru.
Нашли опечатку?
Выделите её, нажмите Ctrl+Enter и отправьте нам уведомление. Спасибо за участие!
Сервис предназначен только для отправки сообщений об орфографических и пунктуационных ошибках.